Postado em 11 de julho de 2013
Zend Framework 2 – Hydrators, Models e o Padrão TableGateway
Atenção! Essa postagem foi escrita há mais de 2 anos. Na informática tudo evolui muito rápido e algumas informações podem estar desatualizadas. Embora o conteúdo possa continuar relevante, lembre-se de levar em conta a data de publicação enquanto estiver lendo. Caso tenha sugestões para atualizá-la, não deixe de comentar!

Introdução
O Zend Framework 2 vem embalado com uma variedade de novos recursos e funcionalidades que agilizam o desenvolvimento em alguns cenários comuns, tais como a interação com bancos de dados, sistema de template, cache, etc.
Não importa se estamos falando dos novos elementos de formulário HTML5 e seus view helpers, a nova implementação do Zend\Http, o Service Manager, o Event Manager ou de tantos outros módulos – é possível perceber que o ZF2 anda arrebentando a boca do balão!
Mas existem alguns recursos que se sobressaem perante aos outros e, recentemente, têm me feito sorrir! Estou falando de: Hydrators, Models e Table Gateways. Se você é novo no ZF2 ou nunca utilizou interação de frameworks com bancos de dados, este artigo foi escrito pra vocês, pois dá uma boa introdução à utilização desses dois juntos.
Alguma vez você já se perguntou para que servem Hydrators ou Table Gateways? Hoje veremos esses componentes mais de perto!
Nós iremos trabalhar com um código de exemplo que ensinará como criar models desacoplados da lógica do recebimento de dados através de uma configuração simples no ServiceManager. Veremos também um não-tão-complexo hydrator que será capaz de extrair informações de uma consulta no banco de dados e preencher o model automaticamente.
Por que essa abordagem?
No Zend Framework 1, quando você precisava ter uma camada de modelo independente da fonte de dados, nem sempre era simples de implementar. Embora se fale muito em PHP e MySQL, todos sabemos que existe uma infinidade de opções, tais como: MongoDB, CouchDB, PostgreSQL, Cassandra, Redis e muito, muito, muito mais.
Algumas aplicações que desenvolvemos, podem começar com necessidades simples, modestas. No começo, talvez um SGBD básico seja suficiente. Mas, conforme suas necessidades mudam e crescem, é bom saber que, sem muita refatoração de código, será possível adaptar seu sistema.
O que veremos hoje é isso! Permitiremos uma fonte de dados quase transparente, pois a camada de modelo não saberá nada sobre essa fonte. Isso vai nos ajudar a assegurar que, independentemente de qual local venha a informação, ela será transformada de uma maneira que o model seja capaz de utilizá-la.
Como funciona?
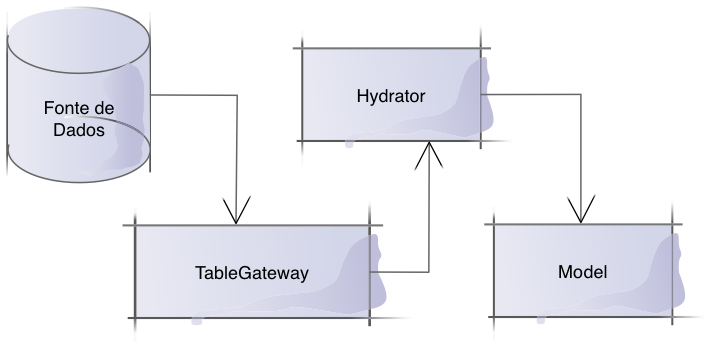
Vou tentar explicar em poucas palavras como funciona. Primeiro, a classe TableGateway realiza a interação específica com a base de dados, como buscar, adicionar, atualizar ou remover dados. Nesse caso, vamos trabalhar com um banco MySQL 5. Então, a classe Hydrator irá mapear (e transformar, quando necessário) a informação recuperada da TableGateway para classe Model.
No método getServiceConfig na nossa classe Module, as duas são unidas e o Hydrator é configurado. Por fim, em uma action do controller poderemos acessar fonte de dados, consultar registros, auto-popular nossa Model e então trabalhar sobre os registros retornados. Ótima ideia, não?
Então vamos lá!
A classe TableGateway
Aqui nós temos a classe TableGateway. Eu a chamei de UserTable, pois ela é responsável por gerenciar informações em uma tabela de usuários. Mantive simples, focando apenas em retornar os registros, deixando de lado as outras operações de CRUD.
No construtor, passamos um objeto TableGateway que será disponibilizado na configuração do ServiceManager. Isso nos fornece um modo simples de acessar o banco de dados. No método fetchAll(), recuperamos um result set chamado o método select() no objeto TableGateway.
As chamadas de buffer() e next() não são exatamente necessárias, mas precisamos incluí-las já que, na ação da listagem, um objeto Paginator é retornado. Erros serão lançados se esses dois métodos não forem chamados.
[php]namespace Phpit\Model;
use Zend\Db\TableGateway\TableGateway;
class UserTable
{
protected $tableGateway;
public function __construct(TableGateway $tableGateway)
{
$this->tableGateway = $tableGateway;
}
public function fetchAll()
{
$resultSet = $this->tableGateway->select();
$resultSet->buffer();
$resultSet->next();
return $resultSet;
}
}[/php]
A classe Modelo
Agora temos a classe User. Como você pode ver, esta classe não tem nenhum código referenciando qualquer tipo de fonte ou banco de dados. Aqui estamos preocupados apenas com os dados que desejamos trabalhar, que neste caso são:
- userId: id do usuário
- userName: nome
- userActive: flag de ativo/inativo
- createdDate: data de criação do registro
O método exchangeArray é comumente utilizado no ZF2 para passar um dataset, nesse caso um array para auto-popular o objeto. É possível ver que eu estabeleci todas as propriedades relacionadas com as chaves respectivas do array. Fácil, limpo e simples.
[php]namespace Phpit\Model;
class User
{
public $userId;
public $userName;
public $userActive;
public $createdDate;
public function exchangeArray($data)
{
if (isset($data[‘userName’])) {
$this->userName = $data[‘userName’];
} else {
$this->userName = null;
}
if (isset($data[‘userActive’])) {
$this->userActive = $data[‘userActive’];
} else {
$this->userActive = null;
}
if (isset($data[‘userId’])) {
$this->userId = $data[‘userId’];
} else {
$this->userId = null;
}
if (isset($data[‘createdDate’])) {
$this->createdDate = $data[‘createdDate’];
} else {
$this->createdDate = null;
}
}
public function getArrayCopy()
{
return get_object_vars($this);
}
}[/php]
O Hydrator
O Hydrator é o aspecto-chave da configuração. É o que mapeia e faz a ligação entre os nomes dos campos no banco de dados e as propriedades da entidade no outro. No entanto, ele não armazena essas informações internamente (como você verá). Tentei ir para uma abordagem mais genérica, uma classe que possa ser aplicada em qualquer tabela.
Com isso nós podemos passar um array de Nomes de Colunas -> Propriedades da Entidade e, quando o método de hydrate for chamado, transferir a informação respectiva da fonte de dados para o objeto de modelo.
[php]namespace Phpit\Hydrator;
use ReflectionMethod;
use Traversable;
use Zend\Stdlib\Exception;
use Zend\Stdlib\Hydrator\AbstractHydrator;
use Zend\Stdlib\Hydrator\HydratorOptionsInterface;
class TableEntityMapper
extends AbstractHydrator
implements HydratorOptionsInterface
{
protected $_dataMap = true;
public function __construct($map)
{
parent::__construct();
$this->_dataMap = $map;
}
public function extract($object) {}[/php]
No método de hydrate, passamos a fonte de dados e o modelo. Se o modelo não for um objeto, nós lançamos uma excessão do tipo BadMethodCallException. Se for, prosseguimos e começamos a iterar sobre os dados disponíveis.
Se não houver um mapeamento disponível, vamos determinar qual campo no modelo corresponde a determinado campo na fonte de dados. Se isso não precisaremos realizar essas determinações (se nenhum mapeamento for necessário), vamos definir a propriedade diretamente. Quaisquer propriedades desconhecidas ou ausentes são silenciosamente ignoradas.
[php] public function hydrate(array $data, $object)
{
if (!is_object($object)) {
throw new Exception\BadMethodCallException(sprintf(
‘%s expects the provided $object to be a PHP object)’,
__METHOD__
));
}
foreach ($data as $property => $value) {
if (!property_exists($this, $property)) {
if (in_array($property, array_keys($this->_dataMap))) {
$_prop = $this->_dataMap[$property];
$object->$_prop = $value;
} else {
// unknown properties are skipped
}
} else {
$object->$property = $value;
}
}
return $object;
}
}[/php]
A configuração do Module Service
Na configuração do Módulo nós iremos juntar tudo. Sem este componente, não seria possível fazer o resto. Em primeiro lugar, vamos registrar um objeto na lista de factories, que inicializará UserTable e passará o objeto para o TableGateway.
Em seguida, temos a configuração do objeto TableGateway. A abordagem que vamos utilizar é baseada no tutorial de hydration do Evan Coury. O que temos aqui é o seguinte: durante a execução o adapter do banco é retornado, nós inicializamos uma instância do hydrator e a alimentamos com o array de mapeamento; os nomes das colunas da tabela à esquerda e as propriedades do modelo à direita. Em seguida, fornecemos o User model como o protótipo a ser usado com o objeto HydratingResultSet. Se você não estiver familiarizado com ele, o HydratingResultSet é uma parte surpreendente do Zend Framework 2. Não vou tentar reinventar a roda, então vou apenas traduzir o que está escrito no manual:
Zend\Db\ResultSet\HydratingResultSet é uma versão mais flexível do objeto ResultSet que permite aos desenvolvedores escolherem uma “estratégia de hydration” (hydration strategy) para pegar dados de uma linha em um objeto-alvo. Enquanto estiver iterado sobre os resultados, HydratingResultSet pegará o protótipo de um objeto-alvo e o clonará para cada linha. O HydratingResultSet então irá preencher (hydrate) esse objeto clone com os dados da linha.
Basicamente, nós fornecemos o modelo e os dados e o hydrator cuida do resto. Depois disso, retornamos um novo objeto TableGateway especificando a tabela referente, tbluser, que será a fonte de dados, o adapter de banco de dados e o objeto de resultset que acabamos de inicializar. Agora, nós temos os dois lados da equação bem unidos. Caso ocorra mudança no nome da tabela, nas propriedades ou nos nomes das colunas, só precisamos fazer pequenos ajustes aqui ou ali. Não há necessidade de tocar em outras classes ou trechos de código.
[php]public function getServiceConfig()
{
return array(
‘factories’ => array(
‘PhpitAdmin\Model\UserTable’ => function($sm) {
$tableGateway = $sm->get(‘UserTableGateway’);
$table = new UserTable($tableGateway);
return $table;
},
‘UserTableGateway’ => function ($sm) {
$dbAdapter = $sm->get(‘Zend\Db\Adapter\Adapter’);
$hydrator = new \Phpit\Hydrator\TableEntityMapper(
array(
‘UserID’ => ‘userId’,
‘UserName’ => ‘userName’,
‘StatusID’ => ‘userActive’,
‘CreatedOn’ => ‘createdDate’
));
$rowObjectPrototype = new \Phpit\Model\User;
$resultSet = new \Zend\Db\ResultSet\HydratingResultSet(
$hydrator, $rowObjectPrototype
);
return new TableGateway(
‘tbluser’, $dbAdapter, null, $resultSet
);
}
)
);
}[/php]
O Controller
Maravilha! Agora está na hora de aprender como usar. No nosso controller nós possuímos uma action de listagem. Ela irá retornar os registros e nós iremos iterar sobre eles.
[php]namespace PhpitManagementAdmin\Controller;
use Zend\Mvc\Controller\AbstractActionController;
use Zend\View\Model\ViewModel;
use Phpit\Model\User;
use Phpit\Form\AddUserForm;
use Phpit\Form\EditUserForm;
class userController extends AbstractActionController
{
protected $userTable;
protected $_createUserForm;
public function listAction()
{[/php]
Em primeiro lugar, recuperamos uma cópia do objeto userTable através do Service Locator. Em seguida, chamamos o método fetchAll(), e recuperamos todas as linhas da tabela. Eu usei um filter iterator e um paginator para deixar o exemplo mais completo.
O filter iterator só retornará registros nos quais o campo userActive estiver definido como “ativo”. Todos os outros serão ignorados. Este iterator é então passado para o objeto Zend\Paginator, algumas propriedades são definidas e então é devolvido no ViewModel, pronto para ser iterado na nossa view.
[php] $sm = $this->getServiceLocator();
$userTable = new \Phpit\Model\UserTable(
$sm->get(‘userTableGateway’)
);
$filterIterator = new StatusFilterIterator(
$userTable->fetchAll(), "active"
);
$paginator = new Paginator(new Iterator($filterIterator));
$paginator->setCurrentPageNumber(
$this->params()->fromRoute(‘page’)
);
$paginator->setItemCountPerPage(
$this->params()->fromRoute(‘perPage’, 10)
);
return new ViewModel(array(
‘paginator’ => $paginator,
‘status’ => $this->params()->fromRoute(‘status’)
));
}
}[/php]
Considerações finais
E, finalmente, estamos prontos. Com apenas um pouquinho de código, criamos um model que é capaz de interagir com uma variedade de fontes de dados e, ao mesmo tempo, conseguimos evitar um acoplamento forte. Se formos sair do MySQL para o PostgreSQL ou o Redis, então poderemos fazer algumas pequenas alterações e tudo estará funcionando novamente.
Eu não sou tão experiente com hydrators, data mappers e table gateway pattern como os outros, portanto adoraria que vocês contassem e dessem suas sugestões para melhorar essa abordagem. Aproveito e deixo a dica de um artigo sobre Strategies, escrito por Jurian Sluiman.
Espero que tenham gostado e que possa ser útil no desenvolvimento.
Um abraço a todos e fiquem com Deus!
Texto adaptado do original: http://www.maltblue.com/tutorial/zendframework2-hydrators-models-tablegateway-pattern
 Meu nome é Rafael Jaques. Sou professor do
Meu nome é Rafael Jaques. Sou professor do