Postado em 10 de maio de 2014
Slides da palestra PHP na Tela Escura
Atenção! Essa postagem foi escrita há mais de 2 anos. Na informática tudo evolui muito rápido e algumas informações podem estar desatualizadas. Embora o conteúdo possa continuar relevante, lembre-se de levar em conta a data de publicação enquanto estiver lendo. Caso tenha sugestões para atualizá-la, não deixe de comentar!

Apresentei ontem no 15º Fórum Internacional de Software Livre a minha palestra intitulada PHP na Tela Escura: Aplicações Poderosas em Linha de Comando.
[slideshare id=34482890&doc=phptelaescurarafajaques-140509090145-phpapp01]
Link para os slides: http://pt.slideshare.net/rafajaques/php-na-tela-escura-aplicaes-poderosas-em-linha-de-comando
Abraços a todos e fiquem com Deus!
Postado em 23 de abril de 2014
PHPit e PHPRS no FISL 15!
Atenção! Essa postagem foi escrita há mais de 2 anos. Na informática tudo evolui muito rápido e algumas informações podem estar desatualizadas. Embora o conteúdo possa continuar relevante, lembre-se de levar em conta a data de publicação enquanto estiver lendo. Caso tenha sugestões para atualizá-la, não deixe de comentar!
![]()
Salve, galera!
Estou aqui para divulgar o 15º Fórum Internacional de Software Livre, aka FISL, que ocorrerá do dia 7 ao dia 10 de Maio de 2014 em Porto Alegre – RS.
Nessa edição estarei comandando duas atividades:
- No dia 9, sexta-feira, apresentarei a palestra PHP na Tela Escura: Aplicações Poderosas em Linha de Comando na sala 41B às 9h (da manhã, hein!).
- No dia 10, sábado, juntamente com o Galvão, vou coordenar o 1º Encontro Comunitário do PHPRS, também às 9 horas da matina, porém na sala 41C.
Além disso, você poderá me encontrar no stand do PHPRS que estará na área de comunidades do FISL.
Aproveite para vir apresentar suas lightning talks, conhecer a galera do PHP e trocar ideias. Espero todos vocês!
Você pode acessar o site do FISL 15 ou a programação do evento.
Um abraço a todos e fiquem com Deus.
Postado em 4 de abril de 2014
Novidade no PHP 5.6: Funções Variádicas e Desempacotamento de Argumentos
Atenção! Essa postagem foi escrita há mais de 2 anos. Na informática tudo evolui muito rápido e algumas informações podem estar desatualizadas. Embora o conteúdo possa continuar relevante, lembre-se de levar em conta a data de publicação enquanto estiver lendo. Caso tenha sugestões para atualizá-la, não deixe de comentar!

Enquanto o PHP 6 não sai, vão surgindo novidades na versão anterior.
Hoje quero apresentar pra vocês duas coisas sensacionais: funções variádicas e desempacotamento de argumentos!
O que raios são funções variádicas?
São funções que permitem a passagem de um número indeterminado de argumentos. É comum no PHP a utilização de funções cujos os primeiros parâmetros sejam fixos e os subsequentes variam.
Um exemplo de função variádica no PHP é array_merge(). Podemos ver o protótipo dela na página do PHP:
[code]array array_merge ( array $array1 [, array $array2 [, array $… ]] )[/code]
Pelo protótipo podemos ver que é possível fundir um número infinito de arrays utilizando essa função.
Antigamente era possível criar funções assim no PHP através da utilização da função func_get_args(). Essa função retorna todos os argumentos passados para uma função, independentemente se foram declarados ou não. No caso das funções variádicas é mais fácil de realizar essa declaração.
Utilizando funções variádicas
Vamos construir uma função para receber valores indeterminados e separá-los por um caractere específico:
[php]function juntar($caractere, …$strings) {
// Como $strings será um array com todos os valores passados
// podemos utilizar o implode pra juntar tudo
return implode($caractere, $strings);
}[/php]
Você pode passar dois parâmetros, no mínimo, para essa função. O primeiro parâmetro é estático e todos os subsequentes serão colocados em um array.
Podemos também criar uma função para imprimir vários valores com um \n no final:
[php]function quebrar_linha(…$linhas) {
foreach ($linhas as $linha) {
echo $linha . ‘\n’;
}
}[/php]
Desempacotamento de argumentos
Outra coisa bacana no PHP 5.6 é a possibilidade de utilizar o mesmo operador para avisar ao PHP que deve desempacotar o array que está sendo passado.
Para esse exemplo podemos utilizar a função mail(). Para ela são suficientes três parâmetros e vamos utilizá-los da seguinte maneira:
[php]$email[] = ‘fulano@site.com’;
$email[] = ‘Assunto’;
$email[] = ‘Mensagem’;
mail(…$email);
[/php]
O operador variádico (alguns chamam de “splat operator”) indica ao PHP que deve desempacotar os valores do array e separar entre os argumentos.
Considerações
PHP é uma linguagem em constante evolução. Tão logo esta versão nova seja lançada e possamos colocá-la em produção, vou postar novos tutoriais demonstrando a utilização de novas funcionalidades.
Espero que tenham gostado do post de hoje!
Um abraço a todos e fiquem com Deus!

Postado em 30 de agosto de 2013
Trabalhando com processos de longa duração no PHP
Atenção! Essa postagem foi escrita há mais de 2 anos. Na informática tudo evolui muito rápido e algumas informações podem estar desatualizadas. Embora o conteúdo possa continuar relevante, lembre-se de levar em conta a data de publicação enquanto estiver lendo. Caso tenha sugestões para atualizá-la, não deixe de comentar!
Para trabalhar com processos de longa duração, como daemons e serviços que ficam rodando o tempo todo no servidor, utilizando o PHP, é necessário ter alguns conhecimentos específicos.
Gostaria de apresentar dois exemplos reais que requerem processos PHP que rodem por longos períodos de tempo (ou até indefinidamente):
- Processamento de dados: Todas as noites o seu servidor precisa vasculhar milhões de dados para atualizar rankings, tabelas e estatísticas.
- Dados da API de Streaming do Twitter: Requer uma conexão constante com a API do Twitter para receber as mensagens conforme elas são postadas.
As ferramentas
Uma das melhores ferramentas que temos é o PHP CLI (Command Line Interface). Essa ferramenta permite que possamos rodar o PHP diretamente da linha de comando (mais conhecido como Terminal) sem possuir um tempo limite. Todas as dores com o set_time_limit() e as brigas com o php.ini vão embora!
Se você vai trabalhar com linha de comando, provavelmente você vai precisar saber um pouquinho de bash scripting. Deixo aqui uma dica: http://aurelio.net/shell/ – uma fonte ilimitada de conhecimento sobre shell/bash.
Outra coisa bacana é o cron (crontab / cron job)
SSH vs Cron Jobs
Você precisa saber rodar algo em uma sessão SSH é diferente do que configurar um cronjob pra fazer algo pra você. Uma sessão SSH pode ser um bom lugar para testar scripts e rodá-los uma vez apenas, enquanto um cronjob é a maneira correta de configurar um script que você deseja que rode regularmente.
Se eu escrever isso na minha sessão SSH
php meuScript.php
irei executar o meuScript.php. Contudo, meu terminal ficará bloqueado até que a execução seja encerrada.
Você pode passar por isso segurando Ctrl + Z (pausa a execução) e utilizando o comando bg (envia o processo para o background).
Para processos longos, pode ser bacana, mas se você perder a sessão SSH, a execução do script será encerrada.
Você pode driblar esse problema utilizando o nohup (no hangup – “não deixar cair”).
nohup php meuScript.php
O comando nohup permite que a execução continue mesmo que você perca a sessão. Isso quer dizer que se você utilizar esse comando, enviar o processo para o background e perder a conexão com o SSH, seu comando continuará rodando.
Mas ainda acho que a melhor maneira de executar um processo diretamente no background é utilizando um & (ampersand – “e comercial”). Você adiciona no final do comando e ele vai diretamente para o background, sem precisar de nenhum atalho.
nohup php meuScript.php &
É claro que tudo isso apenas importa se você estiver rodando comandos manualmente. Se você scripts com uma certa regularidade e usando os cronjobs, então você não precisa se preocupar com esses problemas. Uma vez que é o próprio servidor quem os executa, a sessão SSH não interessa pra nada.
Algumas vezes, você pode esquecer se rodar o processo utilizando o comando nohup e, mesmo assim, querer que ele continue rodando após a desconexão do SSH. Você pode tentar rodar scripts de madrugada, por achar que serão mais rápidos, e acabar descobrindo que eles demoram muito mais. Aqui fica uma pequena dica que vai te ajudar a rodar o script como daemon, assim não se encerrará ao término da sessão SSH.
Ctrl + Zpara pausar o programa e voltar ao shellbgpara rodar no backgrounddisown -h [num-job], onde [num-job] é o número do job que está rodando (exemplo: %1 para o primeiro job rodando; você pode listar os jobs usando o comandojobs). Isso retirará sua propriedade do processo e ele não se encerrará após a saída do terminal.
Créditos da solução ao usuário Node no StackOverflow
Processando dados com PHP
Para quem roda scripts regularmente, é interessante criar um bash script para ser executado por um job agendado.
Exemplo de um bash script que, na verdade, roda um script PHP:
Example bash script which actually runs the PHP script:
#!/bin/sh php /caminho/para/script.phpb
Exemplo de um cronjob:
0 23 * * * /bin/sh /caminho/para/bashScript.sh
Se você não sabe onde colocar o código acima, utilize o comando crontab -e para editar a sua tabela do cron e salvá-la. O 0 23 * * * indica que o script rodará aos 0 minutos, 23 horas de qualquer dia, em qualquer mês e em qualquer dia da semana (agradeço ao mbodock, que me alertou um detalhe que eu havia deixado passar aqui).
# * * * * * comando # ┬ ┬ ┬ ┬ ┬ # │ │ │ │ │ # │ │ │ │ │ # │ │ │ │ └───── dia da semana (0 - 6) (sunday - saturday) # │ │ │ └────────── mês (1 - 12) # │ │ └─────────────── dia do mês (1 - 31) # │ └──────────────────── hora (0 - 23) # └───────────────────────── minuto (0 - 59)
Exemplo extraído do artigo Cron da Wikipedia.
Vale também ressaltar que existem alguns nomes pré-definidos que você pode utilizar no lugar do horário de agendamento:
| Abreviação | Descrição | Equivalente a |
|---|---|---|
| @yearly (ou @annually) | Uma vez por ano, à meia-noite de 1º de Janeiro | 0 0 1 1 * |
| @monthly | Uma vez por mês, à meia-noite do primeiro dia do mês | 0 0 1 * * |
| @weekly | Uma vez por semana, à meia-noite de domingo | 0 0 * * 0 |
| @daily | Uma vez por dia, à meia-noite | 0 0 * * * |
| @hourly | Uma vez por hora, no começo da hora | 0 * * * * |
| @reboot | Quando a máquina é inicializada | @reboot |
Bom, agora nós temos um script básico que rodará todas as noites às 11h. Não importa quanto tempo levará para executar, apenas irá começar às 23h e só encerrará quando terminar.
Twitter Streaming API
O segundo problema é mais interessante, porque o script PHP precisa estar rodando para coletar dados. Queremos que esteja rodando o tempo todo.
Para fazer o trabalho de capturar os dados da API do Twitter, podemos usar a excelente biblioteca Phirehose (fica a dica).
A partir daí, teremos um script que manterá permanentemente uma conexão aberta com a API do Twitter, mas não podemos garantir que estará sempre rodando. O servidor pode reiniciar, podemos ter algum tipo de problema na execução ou erros de qualquer outra natureza.
Então uma solução que podemos lançar mão é: criar um bash script para ter certeza de que o processo está rodando. E se não estiver, que comece a rodá-lo.
#!/bin/sh ps aux | grep '[m]euScript.php' if [ $? -ne 0 ] then php /caminho/para/meuScript.php fi
Agora vamos dar uma olhada, linha por linha, o que faz esse script:
#!/bin/sh
Inicia o script indicando qual é o path do shell.
ps aux | grep '[m]euScript.php'
O comando ps lista os processos. Depois há um pipe (|) que fará com que seja executado um comando sobre o resultado da saída. O comando grep irá procurar por ‘[m]euScript.php’. Usei a expressão regular [m] para que o comando não encontre a ele mesmo. O grep lançará um processo com meuScript.php no comando, então você sempre encontrará um resultado se não colocar alguma coisa nos brackets.
if [ $? -ne 0 ]
Verifica o retorno do último comando. Então se nada for retornado, significa que não existe nenhum resultado para [m]euScript na lista de processos.
then php /caminho/para/meuScript.php fi
Essas linhas são executadas se o script php não for encontrado rodando. É esse comando que irá rodar nosso script php. Então a condicional é encerrada com fi.
Agora vamos criar um cron job para executar o script acima:
* * * * * /bin/sh rodarPraSempre.sh
Isso fará com que o sistema fique checando o tempo todo se o nosso script está rodando. Se não estiver, fará rodar.
Considerações finais
Dá pra perceber que o script de streaming do Twitter é uma versão mais avançada do processamento de dados. Ambas as versões de produção, possuem muito mais coisas, obviamente, mas vão além do objetivo proposto nesse artigo. Se você estiver interessado em estender esses scripts, é uma boa ideia ativar o sistema de logs, pois vai te ajudar a ter uma noção de como o seu sistema está se comportando.
Um abraço a todos e fiquem com Deus!
Rafael Jaques
Texto adaptado do original: http://reviewsignal.com/blog/2013/08/22/long-running-processes-in-php/
Postado em 26 de agosto de 2013
Escalando PHP e MySQL: preparando uma startup para crescer
Atenção! Essa postagem foi escrita há mais de 2 anos. Na informática tudo evolui muito rápido e algumas informações podem estar desatualizadas. Embora o conteúdo possa continuar relevante, lembre-se de levar em conta a data de publicação enquanto estiver lendo. Caso tenha sugestões para atualizá-la, não deixe de comentar!

PHP e MySQL são excelentes alternativas para startups que planejam escalar sua infraestrutura desde a concepção do negócio.
Negócios online começam como um conceito na mente de um empresário e, geralmente, de início são implementados em um único servidor ou em um pequeno cluster. E se você for analisar, verá que realmente não faz sentido investir em uma estrutura grande se você não possui sequer um usuário. Até gigantes, como o Google, começaram assim. O hardware que eles possuíam no começo não impressionaria ninguém.

Primeiro “data center” do Google
Nós todos sabemos o que aconteceu ao Google: em menos de cinco anos eles dominaram o mercado de buscadores e passaram a ocupar enormes data centers com design feito sob medida.
Algo semelhante, embora em uma escala menor, é o sonho da maioria dos empreendedores, mas para chegar lá é necessário pensar em escalabilidade dos servidores originais até algo que possa suportar uma carga muito mais pesada.
O plano de escalonamento deve ser desenvolvido muito antes de qualquer necessidade de crescer, porque se não houver plano, quando chegar a hora, será muito mais difícil e dispendioso – leia-se caro – do que o necessário.
Escalabilidade a partir do design
Uma maneira de escalar é ir aumentando progressivamente a capacidade do servidor com mais hardware, ou transferir gradualmente sua arquitetura para máquinas mais poderosas, mas essa abordagem possui limitações óbvias e pode demandar gastos desnecessários. Quando falamos em escalabilidade, falamos em escalabilidade horizontal, que é o processo de escalada com servidores em cluster e balanceador de carga.
PHP e MySQL comportam-se bem na construção de aplicações que podem escalar suavemente. Contudo, existem três tópicos importantes quando planejamos uma estrutura uma infraestrutura escalável para uma startup: pilha de software, cache e cluster.
Pilha de software
Escolher bem a maneira como vai empilhar seu software é crucial para uma escalada suave. Por exemplo, se você basear sua aplicação em PHP e MySQL mas não possuir um painel de controle que lhe permita adicionar mais nodes no seu MySQL Server e balancear a carga entre eles, seu negócio terá uma dificuldade considerável em crescer sem substituir pontos-chave da pilha.
Cache
O cache pode ser implementado em diversos pontos em um site ou na infraestrutura da aplicação. É importante para para melhorar o desempenho do hardware existente. Usuários de PHP e MySQL devem investigar o seguinte:
- Memcached —É um sistema distribuído de cacheamento de objetos. Ele armazena objetos de um servidor de back-end, como um MySQL, que podem ser distribuídos através de múltiplos servidores, permitindo um grande aumento de performance quanto às consultas ao banco por dados acessados frequentemente.
- APC (Alternative PHP Cache) — Sistema de opcode cache, que aumenta a performance de aplicações através do cacheamento dos códigos de operação de funções PHP executadas frequentemente.
- XCache — Também é um opcode cacher, criado por um dos desenvolvedores do Lighttpd.
- Zend Opcache — É um componente do Zend Server, que serve para acelerar a execução do PHP através do cache de opcode e otimizações em geral. Ele armazena o bytecode dos scripts pré-compilados em uma memória compartilhada e elimina a leitura de disco e compilação para acessos futuros.
Cluster
No coração de qualquer estratégia de escalada, mora a habilidade de adicionar rapidamente novos nodes de baixo custo e efetuar o balanceamento de carga entre eles. O MySQL pode ser facilmente configurado para usar um número determinado de servidores como slaves para a leitura e um master para a escrita, então se você planejar uma estratégia de escalonamento horizontal, PHP + MySQL é uma excelente combinação.
E lembre-se: planejar nos primeiros estágios de uma startup é algo essencial para assegurar a performance e disponibilidade permaneçam constantes durante a fase de crescimento, sem gerar gastos desnecessários.
Texto adaptado do original: http://www.thewhir.com/blog/php-and-mysql-scaling-preparing-a-startup-for-growth
Imagem: http://www.bitrebels.com/technology/whats-the-storage-capacity-at-google/
Postado em 11 de julho de 2013
Zend Framework 2 – Hydrators, Models e o Padrão TableGateway
Atenção! Essa postagem foi escrita há mais de 2 anos. Na informática tudo evolui muito rápido e algumas informações podem estar desatualizadas. Embora o conteúdo possa continuar relevante, lembre-se de levar em conta a data de publicação enquanto estiver lendo. Caso tenha sugestões para atualizá-la, não deixe de comentar!

Introdução
O Zend Framework 2 vem embalado com uma variedade de novos recursos e funcionalidades que agilizam o desenvolvimento em alguns cenários comuns, tais como a interação com bancos de dados, sistema de template, cache, etc.
Não importa se estamos falando dos novos elementos de formulário HTML5 e seus view helpers, a nova implementação do Zend\Http, o Service Manager, o Event Manager ou de tantos outros módulos – é possível perceber que o ZF2 anda arrebentando a boca do balão!
Mas existem alguns recursos que se sobressaem perante aos outros e, recentemente, têm me feito sorrir! Estou falando de: Hydrators, Models e Table Gateways. Se você é novo no ZF2 ou nunca utilizou interação de frameworks com bancos de dados, este artigo foi escrito pra vocês, pois dá uma boa introdução à utilização desses dois juntos.
Alguma vez você já se perguntou para que servem Hydrators ou Table Gateways? Hoje veremos esses componentes mais de perto!
Nós iremos trabalhar com um código de exemplo que ensinará como criar models desacoplados da lógica do recebimento de dados através de uma configuração simples no ServiceManager. Veremos também um não-tão-complexo hydrator que será capaz de extrair informações de uma consulta no banco de dados e preencher o model automaticamente.
Por que essa abordagem?
No Zend Framework 1, quando você precisava ter uma camada de modelo independente da fonte de dados, nem sempre era simples de implementar. Embora se fale muito em PHP e MySQL, todos sabemos que existe uma infinidade de opções, tais como: MongoDB, CouchDB, PostgreSQL, Cassandra, Redis e muito, muito, muito mais.
Algumas aplicações que desenvolvemos, podem começar com necessidades simples, modestas. No começo, talvez um SGBD básico seja suficiente. Mas, conforme suas necessidades mudam e crescem, é bom saber que, sem muita refatoração de código, será possível adaptar seu sistema.
O que veremos hoje é isso! Permitiremos uma fonte de dados quase transparente, pois a camada de modelo não saberá nada sobre essa fonte. Isso vai nos ajudar a assegurar que, independentemente de qual local venha a informação, ela será transformada de uma maneira que o model seja capaz de utilizá-la.
Como funciona?
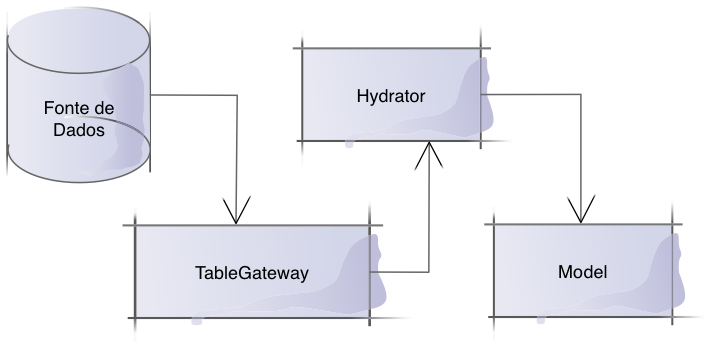
Vou tentar explicar em poucas palavras como funciona. Primeiro, a classe TableGateway realiza a interação específica com a base de dados, como buscar, adicionar, atualizar ou remover dados. Nesse caso, vamos trabalhar com um banco MySQL 5. Então, a classe Hydrator irá mapear (e transformar, quando necessário) a informação recuperada da TableGateway para classe Model.
No método getServiceConfig na nossa classe Module, as duas são unidas e o Hydrator é configurado. Por fim, em uma action do controller poderemos acessar fonte de dados, consultar registros, auto-popular nossa Model e então trabalhar sobre os registros retornados. Ótima ideia, não?
Então vamos lá!
A classe TableGateway
Aqui nós temos a classe TableGateway. Eu a chamei de UserTable, pois ela é responsável por gerenciar informações em uma tabela de usuários. Mantive simples, focando apenas em retornar os registros, deixando de lado as outras operações de CRUD.
No construtor, passamos um objeto TableGateway que será disponibilizado na configuração do ServiceManager. Isso nos fornece um modo simples de acessar o banco de dados. No método fetchAll(), recuperamos um result set chamado o método select() no objeto TableGateway.
As chamadas de buffer() e next() não são exatamente necessárias, mas precisamos incluí-las já que, na ação da listagem, um objeto Paginator é retornado. Erros serão lançados se esses dois métodos não forem chamados.
[php]namespace Phpit\Model;
use Zend\Db\TableGateway\TableGateway;
class UserTable
{
protected $tableGateway;
public function __construct(TableGateway $tableGateway)
{
$this->tableGateway = $tableGateway;
}
public function fetchAll()
{
$resultSet = $this->tableGateway->select();
$resultSet->buffer();
$resultSet->next();
return $resultSet;
}
}[/php]
A classe Modelo
Agora temos a classe User. Como você pode ver, esta classe não tem nenhum código referenciando qualquer tipo de fonte ou banco de dados. Aqui estamos preocupados apenas com os dados que desejamos trabalhar, que neste caso são:
- userId: id do usuário
- userName: nome
- userActive: flag de ativo/inativo
- createdDate: data de criação do registro
O método exchangeArray é comumente utilizado no ZF2 para passar um dataset, nesse caso um array para auto-popular o objeto. É possível ver que eu estabeleci todas as propriedades relacionadas com as chaves respectivas do array. Fácil, limpo e simples.
[php]namespace Phpit\Model;
class User
{
public $userId;
public $userName;
public $userActive;
public $createdDate;
public function exchangeArray($data)
{
if (isset($data[‘userName’])) {
$this->userName = $data[‘userName’];
} else {
$this->userName = null;
}
if (isset($data[‘userActive’])) {
$this->userActive = $data[‘userActive’];
} else {
$this->userActive = null;
}
if (isset($data[‘userId’])) {
$this->userId = $data[‘userId’];
} else {
$this->userId = null;
}
if (isset($data[‘createdDate’])) {
$this->createdDate = $data[‘createdDate’];
} else {
$this->createdDate = null;
}
}
public function getArrayCopy()
{
return get_object_vars($this);
}
}[/php]
O Hydrator
O Hydrator é o aspecto-chave da configuração. É o que mapeia e faz a ligação entre os nomes dos campos no banco de dados e as propriedades da entidade no outro. No entanto, ele não armazena essas informações internamente (como você verá). Tentei ir para uma abordagem mais genérica, uma classe que possa ser aplicada em qualquer tabela.
Com isso nós podemos passar um array de Nomes de Colunas -> Propriedades da Entidade e, quando o método de hydrate for chamado, transferir a informação respectiva da fonte de dados para o objeto de modelo.
[php]namespace Phpit\Hydrator;
use ReflectionMethod;
use Traversable;
use Zend\Stdlib\Exception;
use Zend\Stdlib\Hydrator\AbstractHydrator;
use Zend\Stdlib\Hydrator\HydratorOptionsInterface;
class TableEntityMapper
extends AbstractHydrator
implements HydratorOptionsInterface
{
protected $_dataMap = true;
public function __construct($map)
{
parent::__construct();
$this->_dataMap = $map;
}
public function extract($object) {}[/php]
No método de hydrate, passamos a fonte de dados e o modelo. Se o modelo não for um objeto, nós lançamos uma excessão do tipo BadMethodCallException. Se for, prosseguimos e começamos a iterar sobre os dados disponíveis.
Se não houver um mapeamento disponível, vamos determinar qual campo no modelo corresponde a determinado campo na fonte de dados. Se isso não precisaremos realizar essas determinações (se nenhum mapeamento for necessário), vamos definir a propriedade diretamente. Quaisquer propriedades desconhecidas ou ausentes são silenciosamente ignoradas.
[php] public function hydrate(array $data, $object)
{
if (!is_object($object)) {
throw new Exception\BadMethodCallException(sprintf(
‘%s expects the provided $object to be a PHP object)’,
__METHOD__
));
}
foreach ($data as $property => $value) {
if (!property_exists($this, $property)) {
if (in_array($property, array_keys($this->_dataMap))) {
$_prop = $this->_dataMap[$property];
$object->$_prop = $value;
} else {
// unknown properties are skipped
}
} else {
$object->$property = $value;
}
}
return $object;
}
}[/php]
A configuração do Module Service
Na configuração do Módulo nós iremos juntar tudo. Sem este componente, não seria possível fazer o resto. Em primeiro lugar, vamos registrar um objeto na lista de factories, que inicializará UserTable e passará o objeto para o TableGateway.
Em seguida, temos a configuração do objeto TableGateway. A abordagem que vamos utilizar é baseada no tutorial de hydration do Evan Coury. O que temos aqui é o seguinte: durante a execução o adapter do banco é retornado, nós inicializamos uma instância do hydrator e a alimentamos com o array de mapeamento; os nomes das colunas da tabela à esquerda e as propriedades do modelo à direita. Em seguida, fornecemos o User model como o protótipo a ser usado com o objeto HydratingResultSet. Se você não estiver familiarizado com ele, o HydratingResultSet é uma parte surpreendente do Zend Framework 2. Não vou tentar reinventar a roda, então vou apenas traduzir o que está escrito no manual:
Zend\Db\ResultSet\HydratingResultSet é uma versão mais flexível do objeto ResultSet que permite aos desenvolvedores escolherem uma “estratégia de hydration” (hydration strategy) para pegar dados de uma linha em um objeto-alvo. Enquanto estiver iterado sobre os resultados, HydratingResultSet pegará o protótipo de um objeto-alvo e o clonará para cada linha. O HydratingResultSet então irá preencher (hydrate) esse objeto clone com os dados da linha.
Basicamente, nós fornecemos o modelo e os dados e o hydrator cuida do resto. Depois disso, retornamos um novo objeto TableGateway especificando a tabela referente, tbluser, que será a fonte de dados, o adapter de banco de dados e o objeto de resultset que acabamos de inicializar. Agora, nós temos os dois lados da equação bem unidos. Caso ocorra mudança no nome da tabela, nas propriedades ou nos nomes das colunas, só precisamos fazer pequenos ajustes aqui ou ali. Não há necessidade de tocar em outras classes ou trechos de código.
[php]public function getServiceConfig()
{
return array(
‘factories’ => array(
‘PhpitAdmin\Model\UserTable’ => function($sm) {
$tableGateway = $sm->get(‘UserTableGateway’);
$table = new UserTable($tableGateway);
return $table;
},
‘UserTableGateway’ => function ($sm) {
$dbAdapter = $sm->get(‘Zend\Db\Adapter\Adapter’);
$hydrator = new \Phpit\Hydrator\TableEntityMapper(
array(
‘UserID’ => ‘userId’,
‘UserName’ => ‘userName’,
‘StatusID’ => ‘userActive’,
‘CreatedOn’ => ‘createdDate’
));
$rowObjectPrototype = new \Phpit\Model\User;
$resultSet = new \Zend\Db\ResultSet\HydratingResultSet(
$hydrator, $rowObjectPrototype
);
return new TableGateway(
‘tbluser’, $dbAdapter, null, $resultSet
);
}
)
);
}[/php]
O Controller
Maravilha! Agora está na hora de aprender como usar. No nosso controller nós possuímos uma action de listagem. Ela irá retornar os registros e nós iremos iterar sobre eles.
[php]namespace PhpitManagementAdmin\Controller;
use Zend\Mvc\Controller\AbstractActionController;
use Zend\View\Model\ViewModel;
use Phpit\Model\User;
use Phpit\Form\AddUserForm;
use Phpit\Form\EditUserForm;
class userController extends AbstractActionController
{
protected $userTable;
protected $_createUserForm;
public function listAction()
{[/php]
Em primeiro lugar, recuperamos uma cópia do objeto userTable através do Service Locator. Em seguida, chamamos o método fetchAll(), e recuperamos todas as linhas da tabela. Eu usei um filter iterator e um paginator para deixar o exemplo mais completo.
O filter iterator só retornará registros nos quais o campo userActive estiver definido como “ativo”. Todos os outros serão ignorados. Este iterator é então passado para o objeto Zend\Paginator, algumas propriedades são definidas e então é devolvido no ViewModel, pronto para ser iterado na nossa view.
[php] $sm = $this->getServiceLocator();
$userTable = new \Phpit\Model\UserTable(
$sm->get(‘userTableGateway’)
);
$filterIterator = new StatusFilterIterator(
$userTable->fetchAll(), "active"
);
$paginator = new Paginator(new Iterator($filterIterator));
$paginator->setCurrentPageNumber(
$this->params()->fromRoute(‘page’)
);
$paginator->setItemCountPerPage(
$this->params()->fromRoute(‘perPage’, 10)
);
return new ViewModel(array(
‘paginator’ => $paginator,
‘status’ => $this->params()->fromRoute(‘status’)
));
}
}[/php]
Considerações finais
E, finalmente, estamos prontos. Com apenas um pouquinho de código, criamos um model que é capaz de interagir com uma variedade de fontes de dados e, ao mesmo tempo, conseguimos evitar um acoplamento forte. Se formos sair do MySQL para o PostgreSQL ou o Redis, então poderemos fazer algumas pequenas alterações e tudo estará funcionando novamente.
Eu não sou tão experiente com hydrators, data mappers e table gateway pattern como os outros, portanto adoraria que vocês contassem e dessem suas sugestões para melhorar essa abordagem. Aproveito e deixo a dica de um artigo sobre Strategies, escrito por Jurian Sluiman.
Espero que tenham gostado e que possa ser útil no desenvolvimento.
Um abraço a todos e fiquem com Deus!
Texto adaptado do original: http://www.maltblue.com/tutorial/zendframework2-hydrators-models-tablegateway-pattern
 Meu nome é Rafael Jaques. Sou professor do
Meu nome é Rafael Jaques. Sou professor do